Цель оценки эффективности, которую некоторые уже назвали «формулой несчастья» – как раз сделать тестировщика счастливым, чтобы можно было цифрами показать, что один работает хорошо, и его надо погладить за это по голове, а другой плохой – и его надо пороть… Оценка только по этому критерию не может быть единственной, поэтому должна рассматриваться в совокупности с другими показателями, такими как выполнение плана, автоматизация тестирования и т.п.
Эффективность работы тестировщика, как и любого другого сотрудника, должна быть оценена количественно, т.е. в измеримых показателя. Но какие именно показатели выбрать?
Первое, что приходит на ум, – по количеству найденных дефектов. И именно этот показатель я сходу пытался ввести в «Инрэко ЛАН». Однако сразу же возникла бурная дискуссия, которая и подтолкнула меня к анализу данного критерия. На эту тему я и хочу порассуждать в этой статье.
Количество найденных дефектов - крайне скользкий показатель. Об этом же твердят и все ресурсы в сети, обсуждающие данную проблему (http://www.software-testing.ru/ , blogs.msdn.com/imtesty , it4business.ru , sqadotby.blogspot.com , blogs.msdn.com/larryosterman , sql.ru , http://www.testingperspective.com/ и много-много других). Проанализировав собственный опыт и эти ресурсы, я пришел к следующему дереву проблем:
Во-первых, дефект дефекту – рознь. Один тестировщик может искать дефекты в расположении кнопочек в приложении, другой – копаться в логике и придумывать сложные тестовые ситуации. В большинстве случаев первый тестировщик найдет больше дефектов, потому что даже на подготовку теста у него будет уходить гораздо меньше времени, но ценность таких дефектов значительно ниже. Эта проблема легко решается введением критичности дефекта. Можно оценивать по количеству найденных дефектов в каждой из категорий. У нас, например, их 4: критичный, значительный, средний и малозначительный. Но поскольку граница определения критичности не совсем четкая, хотя у нас и есть формальные признаки критичности, то можно пойти двумя более надежными путями. Первый - определенная часть найденных дефектов за выделенный период должна быть не малокритичными дефектами. Второй – не учитывать при оценке малозначительные дефекты. Таким образом, мы боремся с желанием тестировщика набрать как можно большее количество дефектов за счет описания мелочных изъянов, заставляя его (или чаще её) копать глубже и находить серьезные дефекты. А они всегда есть, поверьте моему опыту. Я выбрал второй вариант – отбрасывать малозначительные дефекты.
Вторая причина “скользкости” такого критерия – присутствие в системе достаточного количества дефектов, чтобы тестировщик мог их найти. Тут есть три фактора. Первый – сложность логики и технологии системы. Второй - качество кодирования. И третий – стадия проекта. Разберем по порядку эти три фактора. Сложность логики и технологии, на которой написана система, влияет на потенциальные недочеты, которые могут быть допущены. Причем зависимость здесь далеко не прямая. Если реализовывать простую логику на сложной или незнакомой платформе, то ошибки будут в основном связаны с некорректным использованием технологии реализации. Если реализовывать сложную логику на примитивной платформе, то, скорее всего, ошибки будут связаны как с самой логикой, так и со сложностью реализации такой логики на примитивном языке. То есть нужен баланс при выборе технологии реализации системы. Но часто технологию диктует заказчик или рынок, поэтому повлиять мы вряд ли можем. Значит, остается лишь учитывать этот фактор как некий коэффициент потенциального количества дефектов. Причем значение этого коэффициента, скорее всего, нужно определять экспертным путем.
Качество кодирования. Здесь мы уже точно никак повлиять не можем на разработчика. Зато мы можем: а) опять же экспертно оценить уровень разработчика и включить его как еще один коэффициент и б) постараться предотвратить появление ошибок в коде за счет модульных тестов, сделав обязательным требованием 100% покрытие кода модульными тестами.
Стадия проекта. Давно известно, что найти все дефекты невозможно, разве что для тривиальной программы или случайно, поскольку совершенству нет предела, а любое несовпадение с совершенством можно считать дефектом. Но одно дело, когда проект находится в активной стадии разработки, и совсем другое – когда в фазе поддержки. А если еще учесть факторы сложности системы и технологии и качества кодирования, то понятно, что все это коренным образом влияет на количество дефектов, которые тестировщик способен найти. С приближением проекта к завершению или к фазе поддержки (называем это все условно и определяем сейчас интуитивно) количество дефектов в системе уменьшается, а значит и количество находимых дефектов тоже. И тут нужно определить момент, когда требовать с тестировщика нахождения определенного количества дефектов становится неразумно. Для определения такого момента было бы неплохо знать, какую часть дефектов от общего их числа мы способны найти и сколько дефектов еще осталось в системе. Это тема для отдельной дискуссии, но можно применить достаточно простой и эффективный статистический метод.
На основании статистики предыдущих проектов можно понять с определенной погрешностью, сколько дефектов было в системе и сколько было найдено командой тестирования в различные периоды проекта. Таким образом, можно получить некий среднестатистический показатель эффективности команды тестирования. Его можно декомпозировать по каждому отдельному тестировщику и получить персональную оценку. Чем больше опыта и статистики, тем меньше будет погрешность. Также можно использовать метод «подсева ошибок», когда мы точно знаем, сколько ошибок в системе. Естественно, что нужно учитывать дополнительные факторы, такие как тип системы, сложность логики, платформу и т.п. Так, мы получаем зависимость между фазой проекта и процентом находимых дефектов. Теперь можно применить данную зависимость в обратную сторону: зная число найденных дефектов и текущую фазу проекта, мы можем определить общее число дефектов в нашей системе (с некоторой погрешностью, конечно же). И дальше на основании показателей персональной или общей оценки можно определить, сколько дефектов тестировщик или команда способны найти за оставшийся период времени. Отталкиваясь от этой оценки, уже можно определять критерий эффективности работы тестировщика.
Функция показателя эффективности работы тестировщика может выглядеть следующим образом:
Defects – количество находимых дефектов,
Severity – критичность находимых дефектов,
Complexity – сложность логики системы,
Platform – платформа реализации системы,
Phase – фаза проекта,
Period – рассматриваемый период времени.
А вот уже конкретный критерий, которому должен соответствовать тестировщик, нужно подбирать эмпирически и с учетом специфики конкретной организации.
Учесть все факторы на данный момент пока не удается, однако совместно с нашим ведущим разработчиком Иваном Астафьевым и руководителем проектов Ириной Лагерь, мы пришли к следующей формуле, учитывающей число дефектов и их критичность:
 , где
, где
E – эффективность, определяемая по числу найденных дефектов,
D Заказчик – число дефектов, найденных заказчиком, но которые должен был найти оцениваемый тестировщик,
D Тестировщик – число дефектов, найденных тестировщиком,
k и d – поправочные коэффициенты на общее количество дефектов.
Сразу хочу отметить, что при оценке по этой формуле нужно брать в расчет только те дефекты, которые относятся к области ответственности оцениваемого тестировщика. Если несколько тестировщиков делят ответственность за пропущенный дефект, то этот дефект должен быть учтен при оценке каждого тестировщика. Также при расчете не учитываются малокритичные дефекты.
 Таким образом, мы имеем параболу третьей степени, отражающую критерий интенсивности нахождения дефектов, которому должен соответствовать тестировщик. В общем случае, если оценка тестировщика лежит выше параболы, это значит, что он работает лучше ожиданий, если ниже, то, соответственно, хуже.
Таким образом, мы имеем параболу третьей степени, отражающую критерий интенсивности нахождения дефектов, которому должен соответствовать тестировщик. В общем случае, если оценка тестировщика лежит выше параболы, это значит, что он работает лучше ожиданий, если ниже, то, соответственно, хуже.
Здесь есть нюанс, связанный с общим количеством анализируемых дефектов. Естественно, чем больше статистики, тем лучше, но иногда нужно проанализировать различные этапы проекта, иногда просто требуется оценка по каждому периоду времени. И одно дело, когда за период найдено 4 дефекта и 2 из них – заказчиком, и совсем другое, когда найдено 100 дефектов, и 50 из них - заказчиком. В обоих случаях отношение числа дефектов, найденных заказчиком и тестировщиком, окажется равным 0.5, но мы-то понимаем, что в первом случае не все так плохо, а во втором пора бить в набат.
Без особого успеха попытавшись сделать строгую математическую привязку к общему количеству дефектов, мы приделали, по выражению той же Ирины Лагерь, «костыли» к этой формуле в виде интервалов, для каждого из которых определили свои коэффициенты. Интервала получилось три: для статистики от 1 до 20 дефектов, от 21 до 60 дефектов и для статистики по более чем 60 дефектам.
|
Кол-во дефектов |
k |
d |
Предполагаемая допустимая часть дефектов, найденных заказчиком от общего числа найденных дефектов |
Последний столбец в таблице введен для пояснения того, какое число дефектов допустимо найти заказчику на данной выборке. Соответственно, чем меньше выборка, тем больше может быть погрешность, и тем больше дефектов может быть найдено заказчиком. С точки зрения функции это означает предельное минимальное значение отношение числа дефектов, найденных заказчиком и тестировщиком, после которого эффективность становится отрицательной, или точку пересечения графиком оси X. Т.е. чем меньше выборка, тем правее должно быть пересечение с осью. В управленческом же плане это означает, что чем меньше выборка, тем менее точной является такая оценка, поэтому исходим из принципа, что на меньшей выборке нужно менее строго оценивать тестировщиков.
Имеем графики следующего вида:

Черный график отражает критерий для выборки более 60 дефектов, желтый – для 21-60 дефектов, зеленый – для выборки менее 20 дефектов. Видно, что чем больше выборка, тем левее график пересекает ось X. Как уже говорилось, для оценивающего сотрудника это означает, что чем больше выборка, тем больше можно доверять этой цифре.
Метод оценки заключается в вычислении эффективности работы тестировщика по формуле (2) с учетом поправочных коэффициентов и сравнение этой оценки с требуемым значением на графике. Если оценка выше графика – тестировщик соответствует ожиданиям, если ниже – тестировщик работает ниже требуемой «планки». Также хочу отметить, что все эти цифры были подобраны эмпирически, и для каждой организации они могут быть изменены и подобраны со временем более точно. Поэтому любые комментарии (здесь или в моем личном блоге) и доработки я только приветствую.
Такой метод оценки по соотношению количества найденных дефектов командой тестирования и заказчиком/пользователем/клиентом, мне кажется разумным и более-менее объективным. Правда такую оценку можно провести только после завершения проекта или, как минимум, при наличии активных внешних пользователей системы. Но что делать, если продукт еще не используется? Как в этом случае оценивать работу тестировщика?
Кроме того, такая методика оценки эффективности тестировщика порождает несколько дополнительных проблем:
1.Один дефект начинает делиться на несколько более мелких.
· Руководитель тестирования, заметивший такую ситуацию, должен пресекать ее уже неформальными методами.
2.Управление дефектами становится более сложным из-за увеличивающегося количества дублирующихся записей.
· Правила фиксирования дефектов в систему отслеживания ошибок, включающие обязательный просмотр наличия схожих дефектов, могут помочь решить эту проблему.
3.Отсутствие оценки качества находимых дефектов, поскольку единственной целью тестировщика становится количество дефектов, и, как следствие, отсутствие мотивации у тестировщика к поиску “качественных” дефектов. Все-таки нельзя приравнивать критичность и “качество” дефекта, второе является менее формализуемым понятием.
· Здесь решающую роль должен сыграть “настрой” и тестировщика и руководителя. Только общее правильное (!) понимание значения такой количественной оценки может решить данную проблему.
Резюмируя все вышесказанное, мы приходим к выводу, что оценивать работу тестировщика только по количеству находимых дефектов не только сложно, но и не совсем правильно. Поэтому количество находимых дефектов должно быть лишь одним из показателей интегральной оценки работы тестировщика, причем не в чистом виде, а с учетом перечисленных мной факторов.
В последние годы автоматизированное тестирование стало трендом в области разработки ПО, в некотором смысле, его внедрение стало «данью моде». Однако внедрение и поддержка автоматических тестов – очень ресурсоемкая, соответственно, недешевая процедура. Повсеместное использование этого инструмента чаще всего ведет к значительным финансовым потерям без какого-либо значимого результата.
Как можно при помощи достаточно простого инструмента оценить возможную эффективность использования автотестов на проекте?
Что определяется как «эффективность» автоматизации тестирования?
Наиболее распространенный способ оценки эффективности (прежде всего экономической) является расчет возврата инвестиций (ROI). Вычисляется он достаточно просто, являясь отношением прибыли к затратам. Как только значение ROI переходит единицу – решение возвращает вложенные в него средства и начинает приносить новые.
В случае автоматизации под прибылью понимается экономия на ручном тестировании . Кроме того, что прибыль в данном случае может быть и не явной – например, результаты нахождения дефектов в процессе ad-hoc тестирования инженерами, время которых высвободилось за счет автоматизации. Такую прибыль достаточно сложно рассчитать, поэтому можно либо делать допущение (например +10%) либо опускать.
Однако не всегда экономия является целью внедрения автоматизации. Один из примеров – скорость выполнения тестирования (как по скорости выполнения одного теста, так и по частоте проведения тестирования). По ряду причин скорость тестирования может быть критической для бизнеса – если вложения в автоматизацию окупаются полученной прибылью.
Другой пример – исключение «человеческого фактора» из процесса тестирования систем. Это важно, когда точность и корректность выполнения операций является критической для бизнеса. Цена такой ошибки может быть значительно выше стоимости разработки и поддержки автотеста.
Зачем измерять эффективность?
Измерение эффективности помогает ответить на вопросы: «стоит ли внедрять автоматизацию на проекте?», «когда внедрение принесет нам значимый результат?», «сколько часов ручного тестирования мы заместим?», «можно ли заменить 3 инженеров ручного тестирования на 1 инженера автоматизированного тестирования?» и др.
Данные расчеты могут помочь сформулировать цели (или метрики) для команды автоматизированного тестирования. Например, экономия X часов в месяц ручного тестирования, сокращение расходов на команду тестирования на Y условных единиц.
Процесс тестирования должен быть эффективен в первую очередь с точки зрения компании, в которой он протекает. Компании могут быть интересны следующие параметры процесса тестирования:
- · Время, необходимое для разработки тестов
- · Время, которое занимает один цикл тестирования
- · Квалификация персонала, необходимая для разработки и проведения тестов
Изменив любой из этих параметров, компания может повлиять на качество тестирования. Однако важно понимать, что любая комбинация этих параметров может быть выражена в денежном эквиваленте, и, как правило, у любого конкретного процесса тестирования есть оптимальная комбинация, при которой достигается достаточный уровень качества тестирования при минимальных денежных затратах.
Автоматизируя процесс тестирования, мы, разумеется, меняем процесс тестирования, а вместе с ним поменяется и оптимальная комбинация перечисленных выше параметров. Например, можно ожидать, что увеличится время, необходимое для разработки тестов и повысятся требования к квалификации персонала, при этом сильно понизится, время, занимаемое одним циклом тестирования. Учитывая, что комбинация параметров стала новой, вероятно поменяется и качество тестирования вместе с его стоимостью. Для того чтобы была возможность дать численный эквивалент эффективности процесса тестирования, предлагается зафиксировать параметр качества на определенном уровне. Тогда численной оценкой эффективности определенного способа тестирования будет являться величина инвестиций, необходимая для того, чтобы он обеспечивал некий определенный уровень качества.
Оценка целесообразности автоматизации тестирования производится с помощью подсчета затрат на ручное и автоматизированное тестирование и их сравнение , . Точно посчитать финансовую целесообразность автоматизации тестов обычно невозможно, поскольку она зависит от параметров, которые в процессе разработки продукта могут быть лишь примерно понятно (например, планируемая длина жизненного цикла системы или точный список тестов, подлежащих автоматизации).
Для расчёта инвестиций, необходимых для внедрения и эксплуатации автоматизированных тестов за выделенный период (Ip), используется следующая формула:
I0 - Оценка стартовых инвестиции, которые состоят из затрат на лицензии необходимого программного обеспечения для разработки автотестов, стоимости дополнительных аппаратных средств и.т.п.
C0 - Оценка стоимости разработки и отладки библиотеки автоматических тестов, которая рассчитывается как произведение среднего времени, нужного для написания одного автоматизированного теста одним разработчиком тестов (в часах), умноженное на цену его рабочего часа и на общее количество тестов, которые предстоит автоматизировать.
Ce - Оценка стоимости одного прогона всех автоматизированных тестов, которая рассчитывается как время, необходимое для подготовки к выполнению тестирования, сложенное с средним временем выполнения одного теста одним тестировщиком, умножено на цену рабочего часа и на общее количество тестов. В нашем случае эта переменная принята за 0, поскольку подготовка к циклу тестирования не требуется, а само тестирование не требует дополнительного контроля со стороны работника и происходит полностью автономно.
Ca - Оценка затрат на анализ результатов одной итерации цикла автоматизированного тестирования, которая вычисляется как оценка доли отрицательных тестов, умноженная на количество тестов, на среднее время, необходимое для анализа причин отрицательной оценки одного теста одним тестировщиком, и на цену одного рабочего часа тестировщика.
Cm - Оценка стоимости поддержания автоматизированных тестов в рабочем и актуальном состоянии. Рассчитывается как вероятность появления необходимости изменения одного теста между циклами тестирования, умноженная на количество тестов, на среднее время, необходимое для актуализации одного теста и на цену одного рабочего часа тестировщика.
Оценка стоимости ручного тестирования (Gp) представлена в следующей формуле:

G0 - Оценка стоимости разработки базы тест-кейсов для ручного тестирования.
k - Это количество планируемых прогонов тестов (циклов тестирования) за всё оставшееся время жизненного цикла продукта.
Ge - Оценка стоимости однократного выполнения цикла ручного тестирования, которая рассчитывается как среднее время, затрачиваемое на подготовку к тестированию плюс среднее время, нужное для выполнения одного тест-кейса одним тестировщиком, умноженное на суммарное количество кейсов и на цену одного рабочего часа тестировщика.
Ga - Оценка стоимости анализа результатов для одного прогона цикла ручного тестирования. Вычисляется как оценка средней доли отрицательных тестов в прогоне, умноженная на количество тестов, на среднее время, необходимое для анализа причин отрицательной оценки одного теста одним тестировщиком, и на цену одного рабочего часа тестировщика;
Gm - Оценка стоимости поддержания ручных тестов в актуальном состоянии. Рассчитывается как вероятность появления необходимости изменения одного теста между циклами тестирования, умноженная на количество тестов, на среднее время, необходимое для актуализации одного теста и на цену одного рабочего часа тестировщика .
Каждый раз, когда мы заваливаем очередной релиз, начинается суета. Сразу появляются виноватые, и зачастую – это мы, тестировщики. Наверное это судьба – быть последним звеном в жизненном цикле программного обеспечения, поэтому даже если разработчик тратит уйму времени на написание кода, то никто даже не думает о том, что тестирование – это тоже люди, имеющие определенные возможности.
Выше головы не прыгнуть, но можно же работать по 10-12 часов. Я очень часто слышал такие фразы)))
Когда тестирование не соответствует потребностям бизнеса – то возникает вопрос, зачем вообще тестирование, если они не успевают работать в установленные сроки. Никто не думает о том, что было раньше, почему требования нормально не написали, почему не продумали архитектуру, почему код кривой. Но зато когда у вас дедлайн, а вы не успеваете завершить тестирование, то тут вас сразу начинают карать…
Но это было пару слов о нелегкой жизни тестировщика. Теперь к сути 🙂
После пару таких факапов все начинают задумываться, что не так в нашем процессе тестирования. Возможно, вы, как руководитель, вы понимаете проблемы, но как их донести до руководства? Вопрос?
Руководству нужны цифры, статистика. Простые слова – это вас послушали, покивали головой, сказали – “Давай, делай” и все. После этого все ждут от вас чуда, но даже если вы что-то предприняли и у вас не получилось, вы или Ваш руководитель опять получает по шапке.
Любое изменение должно поддерживаться руководством, а чтобы руководство его поддержало, им нужны цифры, измерения, статистика.
Много раз видел, как из таск-трекеров пытались выгружать различную статистику, говоря, что “Мы снимаем метрики из JIRA”. Но давайте разберемся, что такое метрика.
Метрика - технически или процедурно измеримая величина, характеризующая состояние объекта управления.
Вот посмотрим – наша команда находит 50 дефектов при приемочном тестировании. Это много? Или мало? Говорят ли Вам эти 50 дефектов о состоянии объекта управления, в частности, процесса тестирования?
Наверное, нет.
А если бы Вам сказали, что количество дефектов найденных на приемочном тестировании равно 80%, при том, что должно быть всего 60%. Я думаю тут сразу понятно, что дефектов много, соответственно, мягко говоря, код разработчиков полное г….. неудовлетворителен с точки зрения качества.
Кто-то может сказать, что зачем тогда тестирование? Но я скажу, что дефекты – это время тестирования, а время тестирования – это то, что напрямую влияет на наш дедлайн.
Поэтому нужны не просто метрики, нужны KPI.
KPI – метрика, которая служит индикатором состояния объекта управления. Обязательное условие – наличие целевого значения и установленные допустимые отклонения.
То есть всегда, строя систему метрик, у вас должна быть цель и допустимые отклонения.
Например, Вам необходимо (Ваша цель), чтобы 90% всех дефектов решались с первой итерации. При этом, вы понимаете, что это не всегда возможно, но даже если количество дефектов, решенных с первого раза, будет равняться 70% – это тоже хорошо.
То есть, вы поставили себе цель и допустимое отклонение. Теперь, если вы посчитаете дефекты в релизе и получите значение в 86% – то это конечно не хорошо, но и уже не провал.
Математически это будет выглядеть, как:
Почему 2 формулы? Это связано с тем, что существует понятие восходящих и нисходящих метрик, т.е. когда наше целевое значение стремится к 100% или к 0%.
Т.е. если мы говорим, к примеру, о количестве дефектов, найденных после внедрения в промышленной эксплуатации, то тут, чем меньше, тем лучше, а если мы говорим о покрытии функционала тест-кейсами, то тогда все будет наоборот.
При этом не стоит забывать о том, как рассчитывать ту или иную метрику.
Для того, чтобы получить необходимые нам проценты, штуки и т.д., нужно производить расчет каждой метрики.
Для наглядного примера я расскажу Вам о метрике “Своевременность обработки дефектов тестированием”.
Используя аналогичный подход, о котором я рассказал выше, мы также на основе целевых значений и отклонений формируем показать KPI для метрики.
Не пугайтесь, в жизни это не так сложно, как выглядит на картинке!

Что мы имеем?
Ну понятно, что номер релиза, номер инцидента….
Critical - коэф. 5,
Major - коэф. 3,
Minor - коэф. 1,5.
Далее необходимо указать SLA на время обработки дефекта. Для этого определяется целевое значение и максимально допустимое время ретестирования, аналогично тому, как я описывал это выше для расчета показателей метрик.
Для ответа на эти вопросы мы сразу перенесемся к показателю эффективности и сразу зададим вопрос. А как рассчитать показатель, если значение одного запроса может равняться “нулю”. Если один или несколько показателей будет равно нулевому значению, то итоговый показатель при этом будет очень сильно снижаться, поэтому возникает вопрос, как наш расчет сбалансировать так, чтобы нулевые значения, к примеру, запросов с коэффициентом тяжести “1” не сильно влияли на нашу итоговую оценку.
Вес - это значение, которое необходимо нам для того, чтобы сделать наименьшим влияние запросов на итоговую оценку с низким коэффициентом тяжести, и наоборот, запрос с наибольшим коэффициентом тяжести имеет серьезное влияние на оценку, при условии того, что мы просрочили сроки по данному запросу.
Для того, чтобы у вас не сложилось непонимания в расчетах, введем конкретные переменные для расчета:
х - фактические время, потраченное на ретестирование дефекта;
y - максимально допустимое отклонение;
z - коэффициент тяжести.
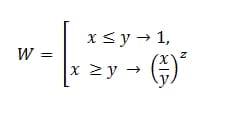
Или на обычно языке, это:
W = E СЛИ (x<=y,1,(x/y)^z)
Таким образом, даже, если мы вышли за установленные нами рамки по SLA, наш запрос в зависимости от тяжести не будет серьезно влиять на наш итоговый показатель.
Все как и описывал выше:
х – фактические время, потраченное на ретестирование дефекта;
y – максимально допустимое отклонение;
z – коэффициент тяжести.
h –
плановое время по SLA
Как это выразить в математической формуле я уже не знаю, поэтому буду писать программным языком с оператором ЕСЛИ.
R = ЕСЛИ(x<=h;1;ЕСЛИ(x<=y;(1/z)/(x/y);0))
В итоге мы получаем, что если мы достигли цели, то наше значение запроса равно 1, если вышли за рамки допустимого отклонения, то рейтинг равен нулевому значению и идет расчет весов.
Если наше значение находится в пределах между целевым и максимально допустимым отклонением, то в зависимости от коэффициента тяжести, наше значение варьируется в диапазоне .
Теперь приведу пару примеров того, как это будет выглядеть в нашей системе метрик.
Для каждого запроса в зависимости от их важности (коэффициент тяжести) имеется свой SLA.
Что мы тут видим.
В первом запросе мы на час всего лишь отклонились от нашего целевого значения и уже имеем рейтинг 30%, при этом во втором запросе мы тоже отклонились всего на один час, но сумма показателей уже равна не 30%, а 42,86%. То есть коэффициенты тяжести играют важную роль в формировании итогового показателя запроса.
При этом в третьем запросе мы нарушили максимально допустимое время и рейтинг равен нулевому значению, но вес запроса изменился, что позволяет нам более правильно посчитать влияние этого запроса на итоговый коэффициент.
Ну и чтобы в этом убедиться, можно просто посчитать, что среднее арифметическое показателей будет равно 43,21%, а у нас получилось 33,49%, что говорит о серьезном влиянии запросов с высокой важностью.
Давайте изменим в системе значения на 1 час.

при этом, для 5-го приоритета значение изменилось на 6%, а для третьего на 5,36%.
Опять же важность запроса влияет на его показатель.
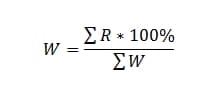
Все, мы получаем итоговый показатель метрики.
Что Важно!
Я не говорю о том, что использование системы метрик нужно делать по аналогии с моими значениями, я лишь предлагаю подход к их ведению и сбору.
В одной организации я видел, что был разработан собственный фреймворк для сбора метрик из HP ALM и JIRA. Это действительно круто. Но важно помнить, что подобный процесс ведения метрик требует серьезного соблюдения регламентных процессов.
Ну и что самое важное – только вы можете решить, как и какие метрики Вам собирать. Не нужно копировать те метрики, которые вы собрать не сможете.
Подход сложный, но действенный.
Попробуйте и возможно у вас тоже получится!
Александр Мешков – Chief Operations Officer в Перфоманс Лаб, – обладает опытом более 5 лет в области тестирования ПО, тест-менеджмента и QA-консалтинга. Эксперт ISTQB, TPI, TMMI.